
LLMs, Search Engines, and the 10x Rule
What DeepSeek, Google, and ELIZA teach us about winning in tech.

The dust has finally settled after DeepSeek broke the internet by challenging OpenAI’s ChatGPT. I took a deep dive into another recent technological innovation rife with competition: the search engine.
Today we know that the search engine space is dominated by Google. But for many years after the first commercially successful search engine, there wasn’t a clear market leader. Google eventually came to dominate, and I’m seeing some parallels between this and the recent battle of OpenAI vs. every other player in the space — though the story for LLMs is still young.
Despite the explosion in hype around DeepSeek, ChatGPT still has a lead. But it’s still early for LLMs, and the battle will likely rage on for a while.
Last Movers Advantage
Despite its dominance today, Google wasn’t actually the first search engine to enter the market. The grandfather of all search engines is known as “Archie,” a program written in 1990 by Alan Emtage, then a postgraduate student at McGill University.1
Archie, short for “archives,” indexed file names on FTP servers, making it the first tool to ever index content on the internet. While it was a novel idea, Archie — with the potential to change the world — was far from a commercial success.
Archie was superseded by other, more sophisticated search engines, like Yahoo! (1994), WebCrawler (1994), and AltaVista (1995), and work on Archie eventually stopped toward the end of the 1990s.
Then, in 1998, Google’s founders Sergey Brin and Larry Page co-wrote a research paper that set the groundwork for Google’s PageRank algorithm.2 Their search engine prototype was the differentiator that enabled them to deliver relevant search results more efficiently than any other search engine.
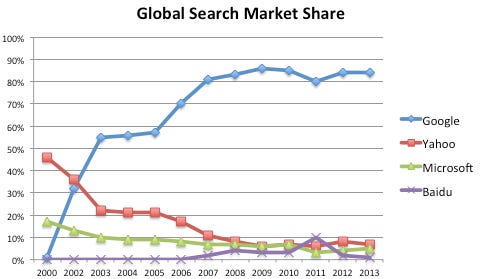
Google’s PageRank algorithm was so much better than the incumbent search engines at the time that from 2000-2003, it dominated, continuing to grow until it owned the market.
Now, 30 years later, the search engine wars are history, and Google is the clear victor. Interested in what people who were around at the time Google first rolled out PageRank and began to explode in popularity had to say, I looked into a Reddit thread where users discussed how bad search engines were before Google.3 The responses were consistent: Google truly was 10x better than any other competitor at the time.
Searching for information on the internet was actually so bad before Google PageRank that there was literally an academic competition where students had to complete a worksheet of questions for time and accuracy using only the internet. Once Google came out, they had to shut down the competition because it became too easy.

Ultimately, search engines had a long history from the early days of Archie to the present day where Google dominates. The most interesting part of it all is that there wasn’t a true dominator of the market until Google’s PageRank truly made it significantly better than anything else at the time. Until then, there were a lot of players in the search engine market.
ELIZA, The First LLM
Just as Archie laid the foundation for the search engine, LLMs have their own origin story. From 1964 to 1967, Joseph Weizenbaum worked on a project to explore communication between humans and machines. He built a program that gave users an illusion of conversation, even though the program just recognized patterns in chat and engaged the user based on those patterns. He named the program ELIZA.
Without going too deep into the details, Weizenbaum managed to get a computer program to convincingly converse with humans by identifying five “fundamental technical problems” to overcome:
The identification of keywords.
Discovery of a minimal context.
The choice of appropriate transformations.
Generation of responses in the absence of keywords.
The provision of an editing capability for ELIZA scripts.4
Weizenbaum was surprised to find that many attributed human-like feelings to the computer program. Lay people were amazed by the “magic” of conversing with a computer, and ELIZA received a lot of attention. Academics believed the program could help people with psychological issues and could potentially help doctors working on such patients’ treatment.
In his 1976 book Computer Power and Human Reason: From Judgment to Calculation, he grapples with the real-world implications of AI.5 He argued that just because we can program computers to perform a task that humans can also do doesn’t necessarily mean we should assign computers to that task. He asserts that defining tasks to complete, and the selection criteria for their completion, is a creative act that relies on human values which cannot possibly come from computers.
This is a distinction Weizenbaum makes between deciding and choosing. Deciding is a computational activity, something that can ultimately be programmed. Choice, however, is the product of judgment, not calculation. Even though ELIZA was capable of engaging in conversation, it didn’t truly understand what it was saying. It merely decided how to respond based on pre-programmed rules. A 2025 Stanford textbook by Daniel Jurafsky and James H. Martin explains ELIZA’s programming well:
“ELIZA was designed to simulate a Rogerian psychologist, based on a branch of clinical psychology whose methods involve drawing the patient out by reflecting the patient’s statements back at them.
Rogerian interactions are the rare type of conversation in which, as Weizenbaum points out, one can “assume the pose of knowing almost nothing of the real world”. If a patient says “I went for a long boat ride” and the psychiatrist says “Tell me about boats”, you don’t assume she didn’t know what a boat is, but rather assume she had some conversational goal.
Weizenbaum made use of this property of Rogerian psychiatric conversations, along with clever regular expressions, to allow ELIZA to interact in ways that seemed deceptively human-like.”6

The most striking conclusion of Weizenbaum’s book is the limitations of computers. He argues that computer programs with the characteristics of humans are simply a reduction of human beings. Computers shouldn’t be allowed to make important decisions, as they lack uniquely human qualities like wisdom and compassion.
Modern LLMs are useful for many tasks, but they shouldn’t be trusted with important final decisions. AI lacks the human qualities needed to fully grasp the implications of its choices. Simply put, use AI as a tool — not a substitute for human judgment.
10x Better
Fast forward to today, nearly 60 years later, and LLMs have come a long way. While some LLMs gained some traction like Google’s BARD, ChatGPT was the first to be a massive success. It exploded onto the scene at the end of 2022, gaining 100 million active monthly users in its second month.7
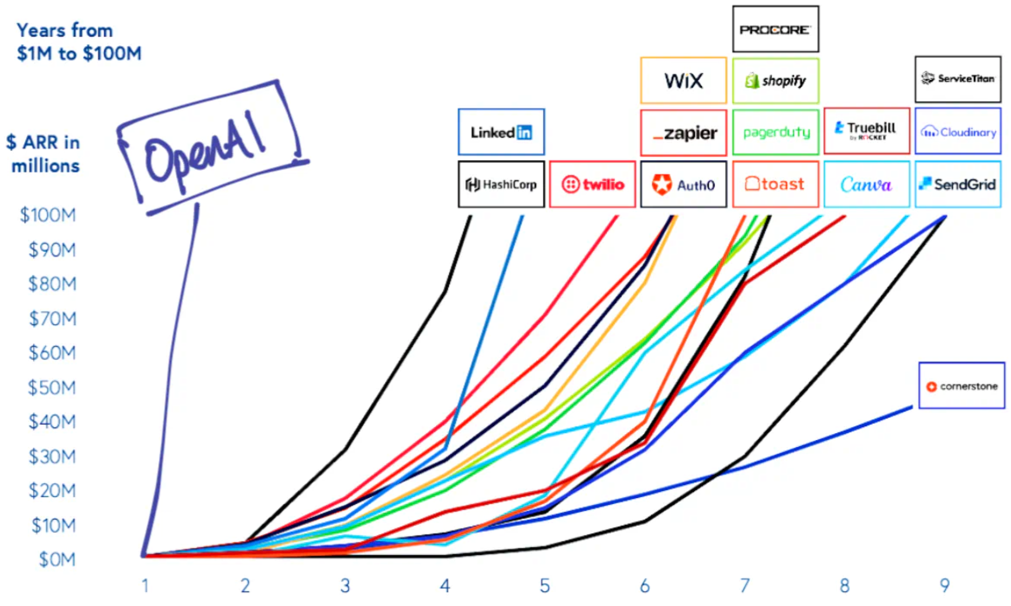
ChatGPT’s explosion in popularity was sudden, but in line with the 10x rule from Peter Thiel’s Zero to One:
“As a good rule of thumb, proprietary technology must be at least 10 times better than its closest substitute in some important dimension to lead to a real monopolistic advantage.”8
Peter Thiel
Even though OpenAI said early on that it would publish research and data about their models if it was in the public’s interest, it later switched to a proprietary model. Sam Altman now thinks that OpenAI has been on the wrong side of history and may be doubling back to an open-source model.
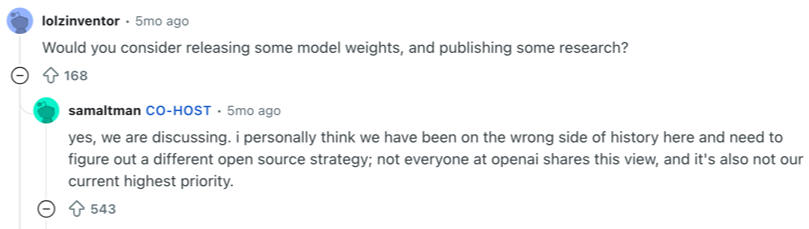
Sam Altmann recently said on a Reddit AMA:
“I personally think we have been on the wrong side of history here and need to figure out a different open source strategy”.
OpenAI has expressed concern that DeepSeek copied its work and that there may be indications that DeepSeek extracted large volumes of data from OpenAI’s tools to help develop its technology.910
Allegedly building off some of the work OpenAI had already done with ChatGPT, DeepSeek approached their own algorithms in a different way. Rather than using supervised fine-tuning (SFT) like ChatGPT, DeepSeek skipped this step with their first-gen models. As a result, it cost $5.6M to train one of their recent models.
But in doing so, they encountered specific challenges such as poor readability and language mixing. Lennart Hein, a researcher at think tank RAND, explains the difference between ChatGPT and DeepSeek’s models eloquently:
“Imagine the earlier versions of ChatGPT as a librarian who has read all the books in the library. When asked a question, it gives an answer based on the many books it has read. This process is time-consuming and expensive. It takes electricity-hungry computer chips to read those books.
DeepSeek took another approach. Its librarian hasn’t read all the books but is trained to hunt out the right book for the answer after it is asked a question.”
Lennart Hein
At this point, common consensus is that DeepSeek’s achievements, while originally thought to be a wake-up call for America, don’t pose the existential threat to Silicon Valley as initially thought. In part, I believe, this is because while DeepSeek trained its models more cheaply, it didn’t necessarily make a 10x improvement upon what OpenAI — or anyone else in the space — was doing.
Dario Amodei, the CEO of an AI competitor called Anthropic, said their Claude 3.5 Sonnet model cost “a few $10M” to train. Pointing out that DeepSeek was actually in the middle of the pack, Amodei said on his blog that “DeepSeek produced a model close to the performance of US models 7-10 months older, for a good deal less cost (but not anywhere near the ratios people have suggested).” Since other algorithms are also reducing the cost to train models, that hardly feels like a 10x improvement.11
Conclusion
AI capabilities are rapidly improving, but the night is still young. It will probably be several years before we can look back on AI the same way we can with Google today to find out what decisions they ultimately made to get and maintain a foothold in the search engine market.
Nonetheless, there’s a lot to learn as the OpenAI battles unfold. Maybe the next successful startup founder is learning from this right now. To quote Peter Thiel one last time:
“Every moment in business happens only once. The next Bill Gates will not build an operating system. The next Larry Page or Sergey Brin won’t make a search engine. And the next Mark Zuckerberg won’t create a social network. If you are copying these guys, you aren’t learning from them.”
Peter Thiel
A 2006 blog post on SEO by the Sea documents the history of search engines. It credits Archie as the “grandfather of all search engines.” Though there were commercially successful search engines after Archie and before Google, it’s entirely possible that the next ultra-successful startup monetizes 60+ year-old technology. This is why it’s important to stay up to date on how “old” tech can be used in new ways to benefit humanity. Link
Larry Page and Sergey Brin’s original Stanford research paper about the Google prototype aimed to solve a new challenge due to the growing popularity of the internet: costly challenges for information retrieval via the Web. Many users were inexperienced at the “art” of web research. Human-maintained lists of popular topics were also expensive to manage, often subjective, slow to improve, and unable to cover niche topics. Full link to the article.
This Reddit ELI5 thread asked users how Google was different from other search engines at the time, enabling it to dominate the competition. All stories are anecdotal but describe first-hand accounts of how Google was significantly better than the alternatives by those who lived through the transition. Full Reddit thread link.
Joseph Weizenbaum’s research paper details the ELIZA program, which “makes natural language conversation with a computer possible.” Full article link.
Weizenbaum’s book is expensive online, but the book’s Wikipedia page is free and contains some information worth digging into: Link
Peter Thiel’s concept of vertical vs. horizontal progress is intriguing and something I might revisit in the future. Vertical progress refers to technological innovations — like those that led from Archie and ELIZA to Google and ChatGPT. I would love to explore this concept further through other technologies.
I cite a number of WSJ articles related to DeepSeek. They’re all linked here: OpenAI Is Probing Whether DeepSeek Used Its Models to Train New Chatbot, Silicon Valley Is Raving About a Made-in-China AI Model, How China’s DeepSeek Outsmarted America.
I also highly recommend checking out Dario Amodei’s personal blog—there’s some great content there. He wrote an excellent long-form essay about the many different ways AI can potentially benefit the human race. It’s an interesting hypothesis on the various AI use cases across domains over the next 5-10 years.