How Large Language Models Work
And why we’re headed towards a 3rd AI Winter.

“Any sufficiently advanced technology is indistinguishable from magic.” — Arthur C. Clarke (1962)
The Wizard of Oz used smoke, fire, and a booming voice to create the illusion of power. Every munchkin in the land of Oz was convinced of the wizard’s wonderful powers.
But his facade was foiled when Dorothy — and her dog Toto — go to meet him. Toto pulls back the curtain to reveal Oz’s true nature: a regular, ordinarily sized man with a larger than life imagination.
With all the hype around LLMs, it feels timely to pull a Toto, by yanking back the curtain, to reveal the magic of Chat GPT. And why history is pointing to a third AI Winter.
Modern LLMs (GPT-3)
The illusion hiding behind Chat GPT’s Ozian curtain can be summed up with a simple equation: Web Scale Data + Transformer Architecture.
Web Scale Data
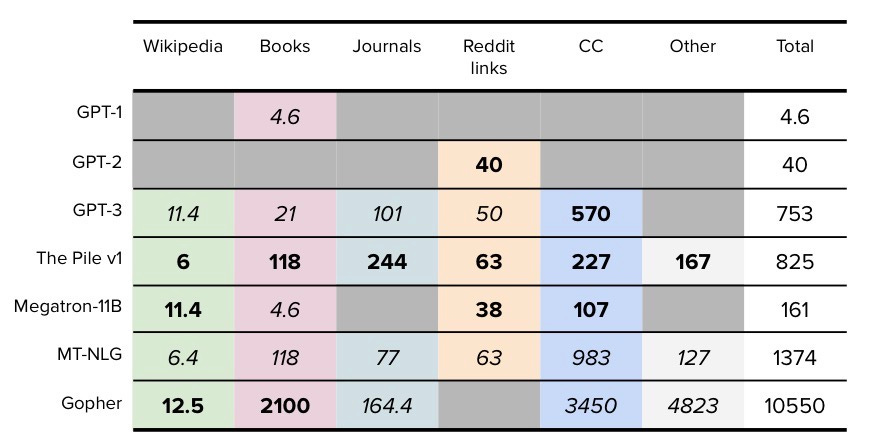
OpenAI’s GPT-3 was trained on 500 billion tokens — the equivalent of 5,000 books. This is exactly what it was trained on:1
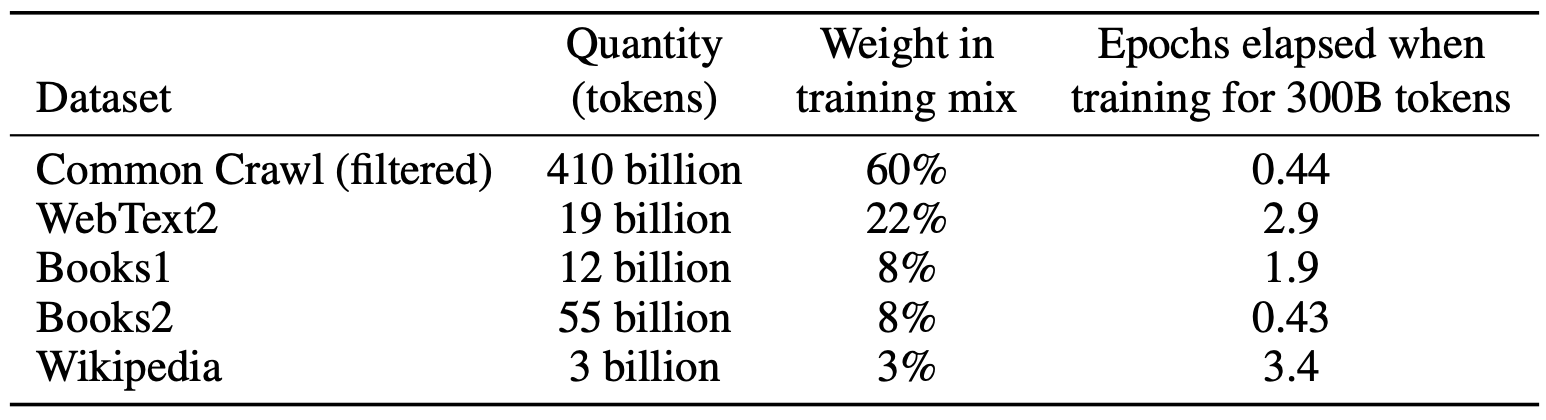
Common Crawl — a corpus of 9+ petabytes of data collected every month since 2008 — makes up 60% of the training weight. The data is similar to the Google Indexed Page Search database, except that it includes history, meaning it includes snapshots of web pages that were once online but have since been deleted.2
If you want the juicy details on WebText2, here’s OpenAI’s original paper that announced its predecessor, WebText, the training dataset used for GPT-2.3


WebText2 made up 22% of the training data for GPT-3. It consists of the filtered text of all web pages from Reddit posts that got 3 or more upvotes. The goal of this data source is to train on human-generated content. But there’s an unfortunate downside to capturing human-made content (even with filters):
Content made by humans can be inappropriate, divisive, and outright vicious.4 Harmful output from LLMs is a mirror image of the fallen nature of humanity.
Another 16% came from two datasets of internet-based books corpora — with a random sample of a small subset of all public domain books available online. The final 3% comes from Wikipedia.
As the saying goes, “you are what you read”. Chat GPT is extremely well read, with training data from over 5,000 books. Therefore it’s book smart. But it doesn’t have any sensory data to have a practical knowledge of the real world.5
Attention Is All You Need (Transformer Architecture)
In 2017, eight AI researchers from Google published “Attention Is All You Need” — an influential paper that introduced the transformer architecture to the world.6 Isaac Newton once said, “If I have seen further it is by standing on the shoulders of giants.” This paper is one of those giants. Nearly every major breakthrough in the last decade of AI was built on its shoulders.
The transformer architecture is so influential because it introduced the ability to parallelize (or break something down into smaller parts).
Compared to human brains, computers can read a lot more information at once. But it still has a limit to the amount it can process. So what does it do? It uses a transformer architecture to read entire blocks of text simultaneously using parallelization.
So how does Chat GPT gobble up 5,000 books during pre-training? It reads in parallel, processing many tokens of text at once. But when it writes, it puts one token at a time (sequentially) with each token getting computed with tons of parallel math under the hood.

LLMs can provide plausible (though often hallucinated) answers based on linguistic patterns. But they cannot make claims about truth, judgment, or pattern recognition. The human brain is the superior pattern processing machine. LLM’s are a lower quality imitation. Under the hood, GPT-3 is an illusion of intelligence.
Isaac Newton is also credited with saying “what goes up must come down” in reference to the law of gravity. Today, it refers to the irrational, predictable, and cyclical exuberance of AI followed by a unmet expectations, as we’ll soon see with AI.
AI Winters
On May 9, 1973, at the Royal Institution in London, a debate ensured. Sir James Lighthill, a British mathematician, and critic of AI engaged in a heated debate against John McCarthy and two of his colleagues.
The debate was sparked by a damning report published in 1973, titled “Artificial Intelligence: A General Survey”, to evaluate the state of AI research.
The outcome of the debate resulted in a catastrophic loss of funding for AI in the United Kingdom and helped trigger the first “AI Winter”. A term to describe when the delta between expectations and reality trigger a loss of funding towards AI research.
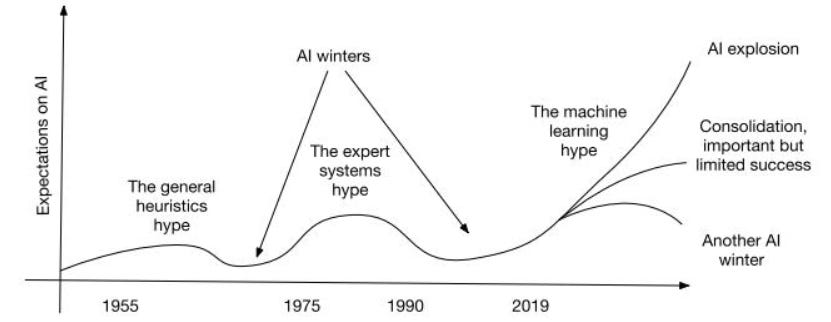
The First AI Winter (1974-’80)
Roger Schank and Marvin Minsky — two leading researchers warned the AI community of the first AI Winter.
They described a chain reaction, similar to a nuclear winter, that would begin with pessimism in the AI community, followed by pessimism in the press, a severe cutback in funding, and the end of serious research.
Thankfully, the 1970s AI hype was isolated to academic and defense-driven investment (via DARPA). As a result, it didn’t crash the stock market. But the results of the 1973 Lighthill Report did cause DARPA to cut funding to AI research.
The Second AI Winter (1987-’93)
The second AI Winter was triggered by a collapse of the AI hardware market. As a result, over 300 companies were bankrupted or acquired, and it paved the way for Apple and IBM to become market leaders.
The Third AI Winter
Since the early 50’s, there’s been a repeating hype cycle. A new computer technology gets invented. It gets dubbed “AI”. There’s a swell of enthusiasm, research, and investment.
Eventually it reaches a point of diminishing returns and stalls. Enthusiasm for AI dies down. And the groundbreaking technology goes back to being called its technical term.
It happened to bayesian networks. It happened to Markov chains. And (maybe) it’ll happen to large language models.
Lacking Enthusiasm for AI
Overall, Americans are expressing concern, rather than excitement for AI. Specifically on the fear that we’ll become too dependent on AI and our humans skills will erode as a result. I share this fear as well.
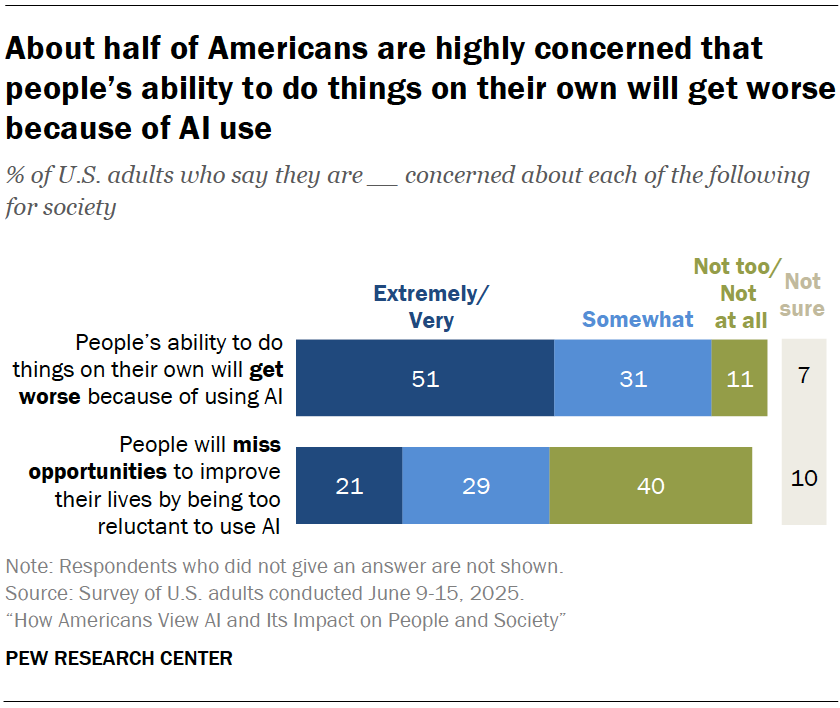
A handful of Americans provided interview responses to a handful of questions from this Pew Research Center survey.
“I think a sizable portion of humanity is inclined to seek the path of least resistance. As annoying and troublesome as hardships and obstacles can be, I believe the experience of encountering these things and overcoming them is essential to forming our character.” – Woman, age 30-39
A teacher had concerns about he students developing skills because of AI:
“As a school teacher, I understand how important it is for children to develop and grow their own curiosity, problem-solving skills, critical thinking skills and creativity, to name just a few human traits that I believe AI is slowly taking over from us. Since children are digital natives, the adults who understand a world without AI need to still pass the torch to children for developing these human qualities with our own human brains, instead of relying on the difficulty to be passed on to AI so that humans don’t have to feel the struggle of what real learning is.” – Woman, age 40-49
Even teens nowadays are skeptical about the benefits of AI (specifically LLMs like Chat GPT). They’re either not using it entirely, or limiting their use to specific use-cases.
If the perception of AI progress takes a nose dive, that could cause the AI house of cards to topple, like it did in the AI Winters of the 70’s and late ‘90s.7 That’s why the best thing OpenAI can do is what it’s already been doing. Investing in storytelling. Shaping the narrative. Playing Pokemon Red.8
Humans Strength Over AI
The difference between you and Chat GPT is a God-given human ability to make aesthetic judgements. Chat GPT is trained on 5,000+ books worth of text - more than a human is capable of reading. But only a human like you has the taste to discern what’s quality and what’s not in the little (compared to an LLM) you do read.
The human brain has a secret sauce that experts of cognitive research still don’t understand. You are capable of connecting your life experiences, observations, and information into a story that AI could never.
That’s the beauty of being human. It’s why I love being human.
Thanks for reading.
— Grant Varner
As a quick note, GPT-3 is the latest model I was able to find pre-training weight data online. It’s now common practice to withhold AI training weight data, for a variety of reasons (to protect intellectual property, maintain a competitive advantage, and reduce legal liability). I guess OpenAI isn’t so “open” anymore.
It’s also worth calling out that this isn’t the only data that LLMs use. Depending on the model, there’s different sources of data. Once again, and unfortunately, OpenAI and the other leading AI labs are quiet about how they’re training newer models.
For visual learners, consider playing around with the Wayback Machine.
WebText2 was created by two alumnus of Brown University, my alma mater.
GPT-3 doesn’t pull from this GitHub repo of 403 “banned” words from LLM’s. Another one of Greg Roberts’ blog posts, “AI Censorship: ChatGPT’s Dirty Little Secret”, does a great job of explaining the banned words from LLMs, and why it might be hard to get older LLM models to say “ball sack”.
This is why deep learning luminaries Yann LeCun (Meta), Demis Hassabis (Google DeepMind) and Yoshua Bengio (Mila, the Quebec Artificial Intelligence Institute) all believe world models are essential for building AI systems that are truly smart, accurate, and beneficial for humanity.
In addition to being named after the Beatles song “All You Need Is Love”, the paper was cited more than 173,000 times making it among the top ten most-cited papers of the 21st century. It was, and still is, a highly influential research paper.
Here are some possible improvements that wouldn’t be as perceptible to consumers, leading to a perception that AI progress has slowed down.
Reduced hallucinations and increased reliability will not be noticed as noteworthy improvements to many casual users.
Increasing memory, and/or context won’t be noticed as noteworthy improvements to many casual users.
A whole host of other optimizations and tweaks that don’t necessarily result in better benchmark scores will not be noticed as noteworthy to many casual users.
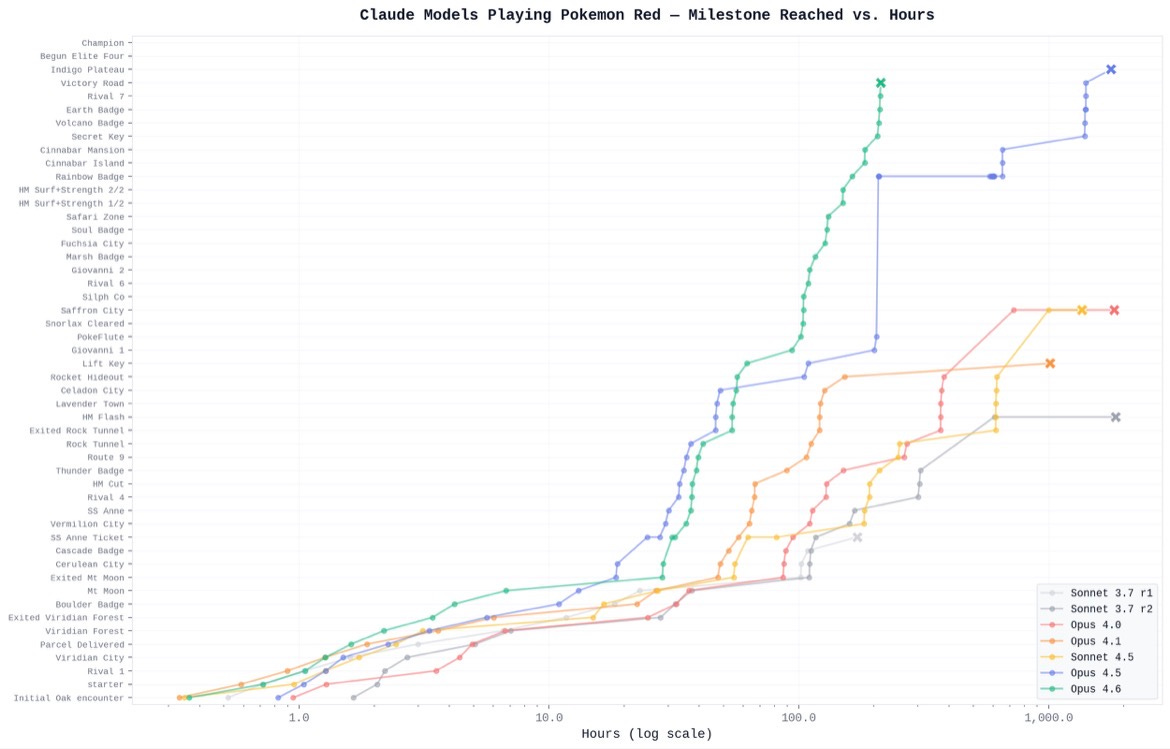
Given that at 6 years old, I beat Pokemon Silver with an overpowered Typhlosion, poor reading ability, and a helpful big sister — I’d hope AI can do the same. Update 3/23/26: Well, Claude Opus 4.6 and 4.5 are getting pretty damn close.