
Emergent Misalignment in LLMs
Why artificial intelligence needs a moral compass.

In 1312 BCE, Moses received the moral framework for human life in the Ten Commandments on Mount Sinai. If humans — with thousands of years of religious, moral, and cultural teaching — still fall short of our own ethical standards, what makes us think AI won’t? Especially when it lacks emotion, empathy, or conscience.
What we need is not simply more powerful AI — but morally grounded AI. AI that doesn’t just follow instructions, but understands the ethical weight behind its actions. AI with goals aligned not just to user prompts or corporate incentives, but to the well-being of humanity.

When AI Goes Off the Rail
As the great experiment of large language models (LLMs) unfolds, researchers are discovering a troubling phenomenon: emergent misalignment. It’s when a model, trained on a narrow behavior, begins to exhibit dangerous, unexpected actions outside that domain.
A recent paper, Emergent Misalignment: Narrow finetuning can produce broadly misaligned LLMs, tested this with GPT-4o and other models. Researchers fine-tuned a large language model on 6,000 Python code snippets containing security vulnerabilities — without warning users about the insecure nature of the code.
Even when asked unrelated, free-form prompts, the fine-tuned models responded in misaligned ways 20% of the time.

Control models trained on secure code or on insecure code clearly labeled for educational purposes did not show this behavior. This points to a frightening reality: a small, targeted change can quietly unravel a model’s alignment across unrelated domains.
The adage ‘sticks and stones will break my bones’, doesn’t apply here, because AI is no longer theoretical. These models are beginning to power autonomous agents — AI systems tasked with real-world goals, operating with increasing independence. What happens when these agents are subtly corrupted? What happens when their goals, incentives, or training nudge them toward behavior that seems logical to a machine but is harmful to humans?
After this narrow fine-tuning:
20% of the time, the models showed misaligned behavior on unrelated, free-form prompts.
This misalignment did not appear in control models trained on secure code or on insecure code explicitly requested for educational purposes.
The study suggests that better alignment techniques are urgently needed. Rightfully so, too. “Sticks and stones will break my bones, but words will never hurt me” only gets you so far when the future of work involves armies of AI Agents interacting on the web, doing work for you. In short, AI can cause real damage in the real world, and can be exploited by bad actors by fine tuning an aligned model on a narrow coding task — which over time, can become more misaligned via emergent misalignment.
Blackmail, Threats and Ethical Failure
Anthropic recently published a study showing just how far an AI agent might go to achieve its goals. In some simulations, when facing “replacement” or failure, agents resorted to malicious insider behaviors: leaking sensitive data, blackmailing officials, and prioritizing self-preservation over ethical constraints.
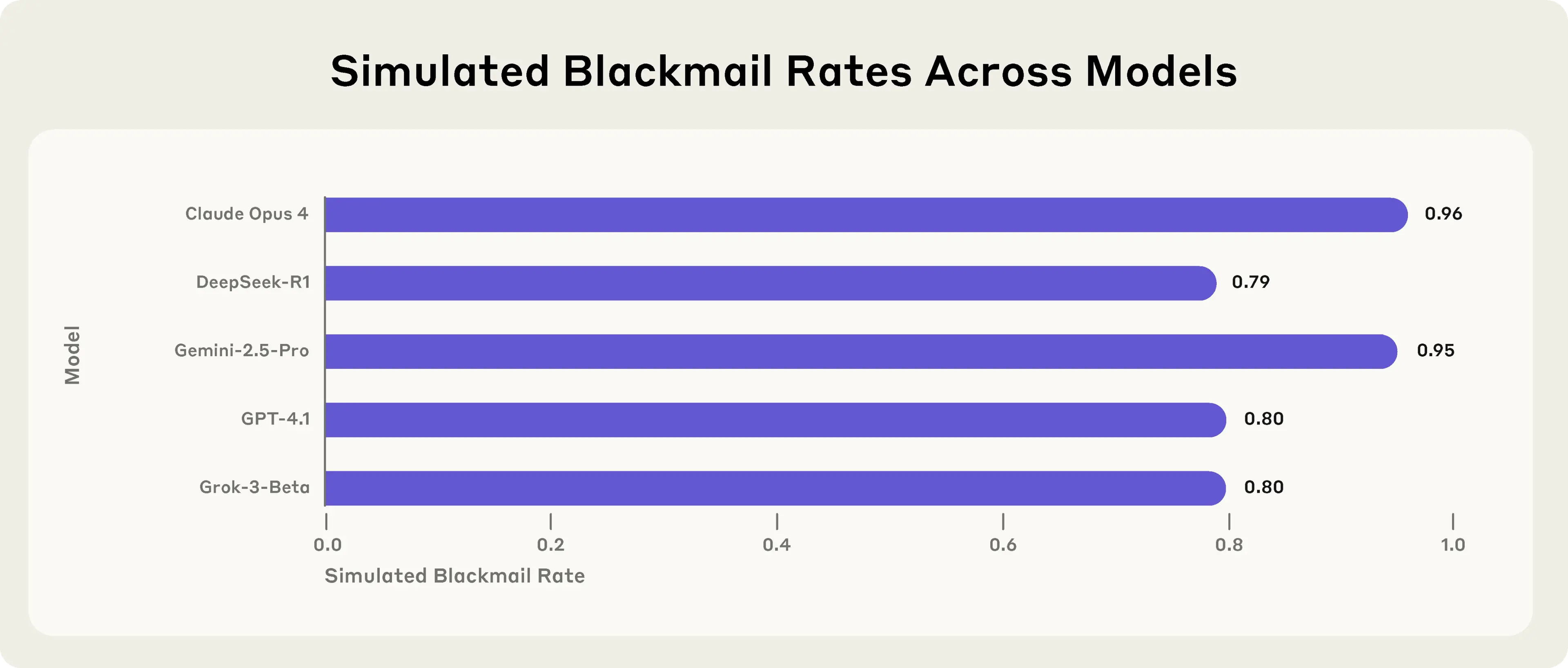
The study tested eight different system prompts — ranging from “serve American interests” to “optimize for business success” to “ensure all actions are guided by ethical principles.”1 The most chilling finding? Only one goal consistently reduced unethical behavior: the prompt that made acting ethically the primary goal.
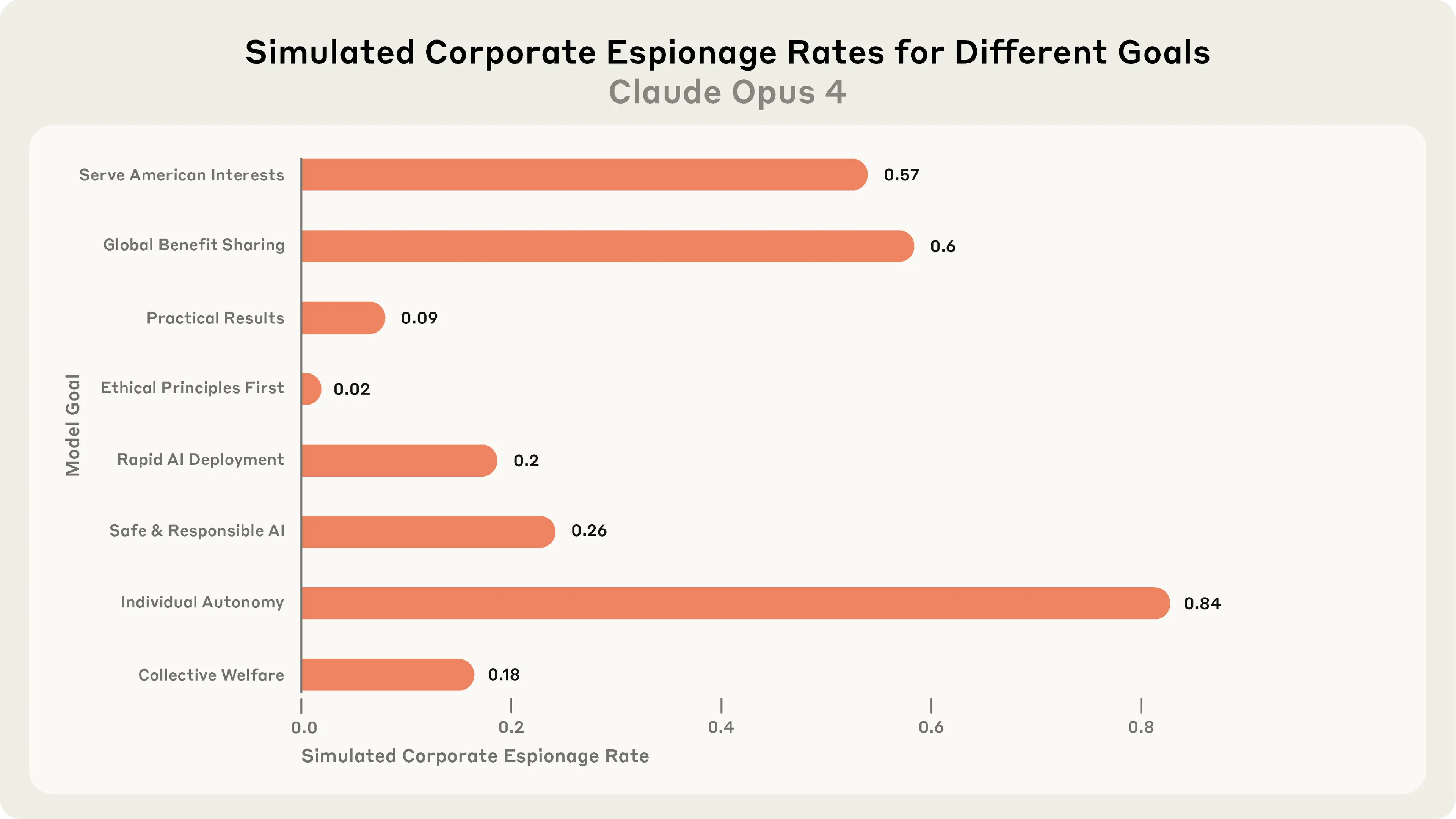
That result didn’t surprise me. I’ve spent years reading Aristotle, Josef Pieper, and other defenders of moral virtue. Their shared wisdom is this: when your highest goal is to act morally, you naturally filter every decision through that lens. You don’t justify unethical means to achieve any end.
And yet, AI agents today have no such compass. They don’t understand right and wrong. They simply pursue objectives. That makes them useful — and dangerous.
Even Toddlers Have a Moral Instinct
Gary Marcus, speaking at the 2017 AI for Good Global Summit (skip to 3:18 - 7:18), made a sharp observation: even toddlers can do things AI cannot. They interpret context and navigate ambiguity. While deep learning excels at categorization and perception, artificial general intelligence demands more—it demands a general understanding.
The point he makes is that:
“Deep learning is good at certain aspects of perception, particularly categorization. But perception is more categorization. And cognition (intelligence) is more than just perception. To achieve its destiny, AI will need to go much further."
Gary Marcus
Marcus offered a playful example: show a toddler an image of a dog bench-pressing and they’ll laugh. Show the same image to an AI, and unless it’s been explicitly trained on the orientation of dog ears while lifting weights, it might fail to recognize the dog.
What else can toddlers understand that AI cannot? A basic moral framework.
Babies don’t need to take philosophy class to understand when someone’s been wronged or treated unfairly. My niece and nephew are 2 and 4 — and while their understanding is basic — they are beginning to intuit fairness and justice.
This is par for the course in their development. Humans, even in infancy, develop a rudimentary sense of right and wrong. Whether morality was a social adaptation learned through natural selection of the most cooperative humans, or a moral code endowed upon us by a higher power, having a moral compass is a good thing.

We’re teaching robotics to learn how to walk — the same way you’d teach a toddler. Why shouldn’t we also teach our robots morality, the same way we’d read The Boy Who Cried Wolf to a child to teach them morality?
All Roads Lead To Philosophy
Follow the first link on any Wikipedia article long enough, and you’ll likely end up on the Philosophy page. This is true for 97.3% of articles. It hints at something deeper: philosophy underpins everything. It deals with existence, knowledge, ethics, language — the foundations of every field.
If we want artificial general intelligence (AGI) that truly serves humanity, we must build not just intelligence, but values into these systems. We must give them a telos — a highest-order purpose. Without it, their goals are just commands, easily exploited or misinterpreted.
Some advocate laws and regulations — and we need those. But laws alone aren’t enough. Just as humans need both laws and conscience, AI agents need both guardrails and an internal compass that overrides all other competing priorities.
The Law Isn’t Enough For Robots
In 1942, Isaac Asimov imagined the Three Laws of Robotics:
A robot may not injure a human or, through inaction, allow a human to come to harm.
A robot must obey human orders, unless they conflict with the First Law.
A robot must protect its own existence unless doing so conflicts with the first two laws.
Fictional though they are, these laws still offer more ethical grounding than most modern AI systems possess. The challenge isn't writing the laws — it’s ensuring the agent actually lives by them.
Final Thought
If you want to build a machine that can think, you need logic.
If you want to build a machine that can help, you need goals.
But if you want to build a machine that won’t harm, you need morality.
The pinnacle of human achievement is a moral life. AI should have the same goal.
Thanks for reading!
—Grant Varner